“索引下推”(Index Condition Pushdown,简称 ICP)是 MySQL 5.6 引入的一项重要查询优化技术。它能显著减少回表次数,提升索引查询效率。
下面我来详细解释:如何分析一个查询是否使用了索引下推(ICP)?
🔍 一、什么是索引下推(ICP)?
🎯 传统流程(无 ICP):
- 存储引擎根据索引查找记录。
- 找到索引项后,立刻回表(通过主键去聚簇索引查完整行数据)。
- 然后由 Server 层判断其他
WHERE条件是否满足。
👉 问题:即使某些记录不满足条件,也先回表,浪费 I/O。
✅ 使用 ICP 后的流程:
- 存储引擎使用索引扫描。
- 在索引层就先判断部分
WHERE条件。 - 只有满足条件的索引项才回表。
👉 好处:减少回表次数,提升性能。
🧩 二、举个例子说明
假设表结构:
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT,city VARCHAR(20),INDEX idx_name_age (name, age));
执行查询:
SELECT * FROM usersWHERE name LIKE '张%'AND age > 30;
- 索引:
(name, age) name LIKE '张%':可用索引定位范围。age > 30:也可用索引,但属于范围条件。
❌ 无 ICP:
- 存储引擎找到所有
name LIKE '张%'的索引项(比如 100 条)。 - 每条都立即回表,取出完整行。
- Server 层再判断
age > 30。 - 最终可能只有 20 条满足,但回表了 100 次 ❌。
✅ 有 ICP:
- 存储引擎在索引层就检查
age > 30。 - 只有同时满足
name LIKE '张%'和age > 30的索引项才回表。 - 回表次数从 100 次降到 20 次 ✅。
🔎 三、如何判断是否使用了 ICP?
使用 EXPLAIN FORMAT=JSON 或查看 Extra 字段。
方法 1:看 EXPLAIN 的 Extra 列
EXPLAIN SELECT * FROM usersWHERE name LIKE '张%' AND age > 30;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | users | range | idx_name_age | idx_name_age | 154 | NULL | 100 | Using index condition |
🔍 关键点:
Extra = Using index condition→ 表示使用了 ICP- 如果是
Using where,则可能是 Server 层过滤,未使用 ICP
✅
Using index condition= 使用了索引下推
❌Using where= 条件由 Server 层处理,可能已回表
方法 2:使用 EXPLAIN FORMAT=JSON(更详细)
EXPLAIN FORMAT=JSONSELECT * FROM users WHERE name LIKE '张%' AND age > 30;
输出中会看到:
"used_columns": ["id", "name", "age", "city"],"attached_condition": "(...)","access_type": "range","index_condition": "((`test`.`users`.`name` like '张%') and (`test`.`users`.`age` > 30))"
🔍 关键字段:
"index_condition":表示在存储引擎层使用的条件 → ICP 生效"attached_condition":Server 层额外过滤的条件
✅ 四、ICP 的使用条件
| 条件 | 是否支持 ICP |
|---|---|
| 联合索引,部分条件无法用索引查找 | ✅ 是(典型场景) |
| 条件字段都在索引中 | ✅ 最佳 |
有函数或表达式(如 UPPER(name)) |
❌ 不支持(除非函数索引) |
| 全文索引 | ❌ 不支持 |
| MyISAM、InnoDB | ✅ 支持 |
覆盖索引(Using index) |
❌ 不需要回表,ICP 无意义 |
🚫 五、什么情况下 ICP 不生效?
覆盖索引:
- 查询字段都在索引中,直接返回,无需回表,ICP 无用武之地。
- 此时
Extra = Using index
条件不能在索引层计算:
- 如
WHERE JSON_EXTRACT(info, '$.age') > 20 - 存储引擎无法解析 JSON,必须回表后由 Server 层处理。
- 如
使用了
LIKE '%abc'这样的前导通配符:- 索引无法有效定位,ICP 效果差。
✅ 六、如何验证 ICP 是否提升了性能?
你可以通过以下方式对比:
关闭 ICP 测试(仅用于测试):
SET optimizer_switch='index_condition_pushdown=off';-- 执行查询,观察 performance_schema 或慢查询日志
开启 ICP:
SET optimizer_switch='index_condition_pushdown=on';
对比:
- 执行时间
Handler_read_next(反映索引扫描次数)- 回表次数(间接体现)
✅ 总结:如何分析是否使用了索引下推?
| 方法 | 判断依据 |
|---|---|
EXPLAIN |
Extra 中出现 Using index condition |
EXPLAIN FORMAT=JSON |
出现 "index_condition" 字段 |
| 性能表现 | 回表次数减少,查询更快 |
| 条件匹配 | 联合索引 + 部分条件可下推到存储引擎 |
🔑 记住:
Using index→ 覆盖索引,无需回表Using where→ Server 层过滤,可能已回表- ✅
Using index condition→ 使用了索引下推(ICP)
如果你有具体的 SQL 和 EXPLAIN 输出,我可以帮你判断是否触发了 ICP。
回表
“回表”是 MySQL 中一个非常重要的概念,尤其在使用 二级索引(Secondary Index) 查询时经常提到。
📌 什么是“回表”?
回表(也叫“回主键查询”或“书签查找” Bookmark Lookup)
指的是:通过二级索引找到记录的主键值后,再根据主键去聚簇索引(Clustered Index)中查找完整数据行的过程。
🔍 为什么需要回表?
这和 MySQL InnoDB 存储引擎的索引结构有关:
1. 聚簇索引(Clustered Index)
- 数据行是按主键顺序存储的。
- 叶子节点存储的是完整的数据行。
- 每张表都有一个聚簇索引(通常是主键)。
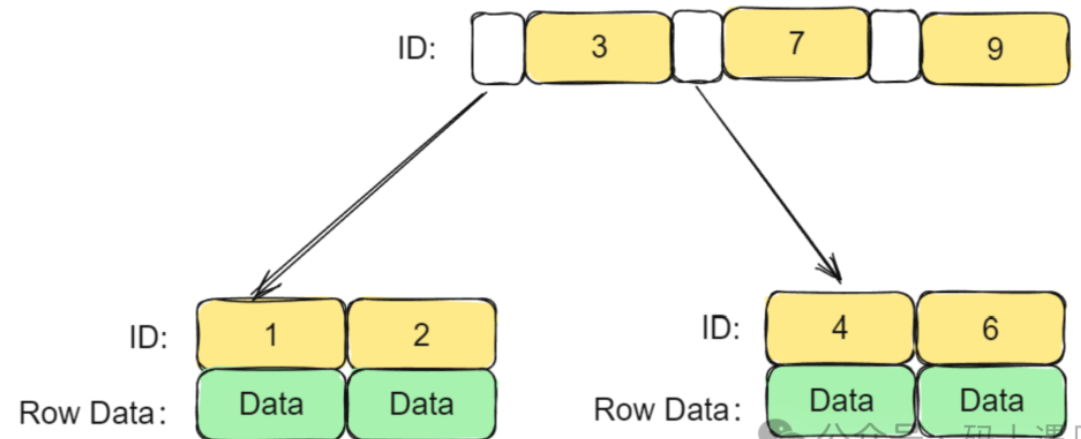
2. 二级索引(Secondary Index)
- 比如你为
name字段创建的索引。 - 叶子节点存储的是:索引字段值 + 主键值。
- 不包含完整的数据行。
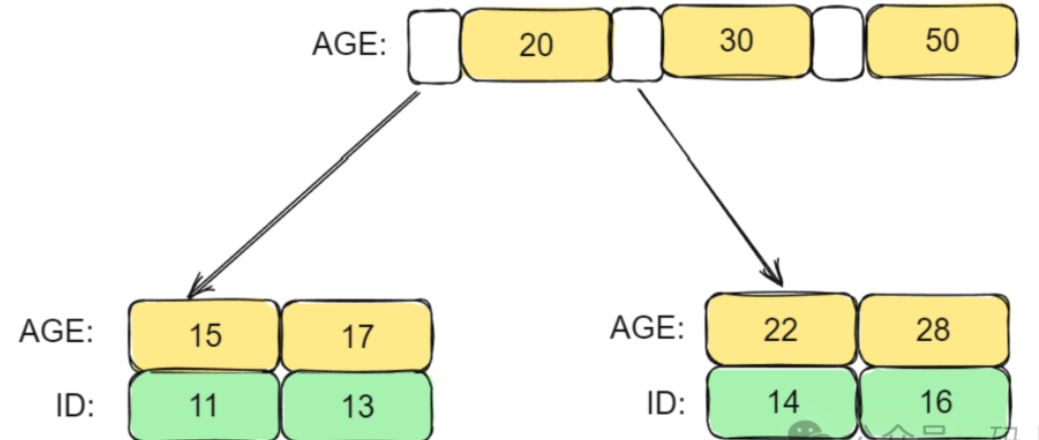
对于聚簇索引,其非叶子节点上存储的是索引值,而叶子节点上存储的是整行记录。
对于非聚簇索引,其非叶子节点上存储的是索引值,而叶子节点上存储的是主键的值以及索引值。
🧩 举个例子
假设有一张表:
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT,INDEX idx_name (name));
数据如下:
| id | name | age |
|---|---|---|
| 1 | 张三 | 25 |
| 2 | 李四 | 30 |
| 3 | 王五 | 28 |
索引 idx_name (name) 的结构类似:
| name | 主键 id |
|---|---|
| 张三 | 1 |
| 李四 | 2 |
| 王五 | 3 |
❓ 执行以下查询会发生什么?
SELECT * FROM users WHERE name = '李四';
步骤分解:
使用二级索引
idx_name查找:- 找到
name = '李四',对应的主键id = 2。 - ✅ 这一步很快,因为索引有序。
- 找到
回表(关键步骤):
- 拿着主键
id = 2,去聚簇索引中查找完整的数据行。 - 找到
id=2, name=李四, age=30。
- 拿着主键
👉 第 2 步就是“回表”。
✅ 回表的代价
- 一次额外的索引查找(主键索引查找)。
- 如果匹配的记录很多(比如几千条),就要回表几千次。
- 每次回表可能涉及磁盘 I/O(尤其是数据不在内存中)。
- 性能下降明显。
🚫 如何避免回表?
使用 覆盖索引(Covering Index)!
如果查询的所有字段都在索引中,就不需要回表。
示例 1:避免回表
SELECT name FROM users WHERE name = '李四';
- 只查
name,而name在idx_name索引中。 - ✅ 不需要回表,直接从索引返回结果。
EXPLAIN中会显示Using index。
示例 2:联合索引避免回表
-- 创建联合索引CREATE INDEX idx_name_age ON users(name, age);-- 查询SELECT name, age FROM users WHERE name = '李四';
name和age都在索引中。- ✅ 覆盖索引,无需回表。
🔍 如何判断是否回表?
看 EXPLAIN 的 Extra 列:
| Extra 信息 | 含义 |
|---|---|
Using index |
✅ 使用了覆盖索引,没有回表 |
Using where; Using index condition |
⚠️ 使用了索引,但需要回表 |
Using where |
❌ 可能全表扫描或回表 |
✅ 总结
| 概念 | 说明 |
|---|---|
| 回表 | 通过二级索引找到主键,再去聚簇索引查完整数据行 |
| 原因 | 二级索引只存主键,不存完整数据 |
| 代价 | 多一次索引查找,影响性能 |
| 避免方法 | 使用覆盖索引(查询字段都在索引中) |
💡 简单记忆:
“回表 = 从二级索引跳回主键索引拿数据”
能避免就尽量避免,用覆盖索引优化。
如果你有具体 SQL,我可以帮你分析是否发生了回表。
